Shift-Left Is Not Broken. It Is Just Not Enough
April 8, 2026

When we onboard a new client, the CI pipeline is usually already green. Coverage numbers look healthy. If shift-left was not in place, we helped them get there without ripping up what worked. Defects caught earlier. Costs were also down, and the C-Suite also noticed the productivity.
Then the same incident would land in the postmortem channel. Different quarter, same conversation. A payment flow failing under a traffic spike no staging environment had ever replicated. An API timeout surfaced only when three downstream services responded slowly at the same time.
🚨A misconfigured deployment that passed every check and broke one specific user journey in production.
None of it showed up in the pipeline. All of it showed up in the postmortem.
The moment we extended coverage into deployment validation and runtime monitoring, the pattern broke. Not because the engineers got better. Because the strategy finally matched the system it was supposed to be protecting.
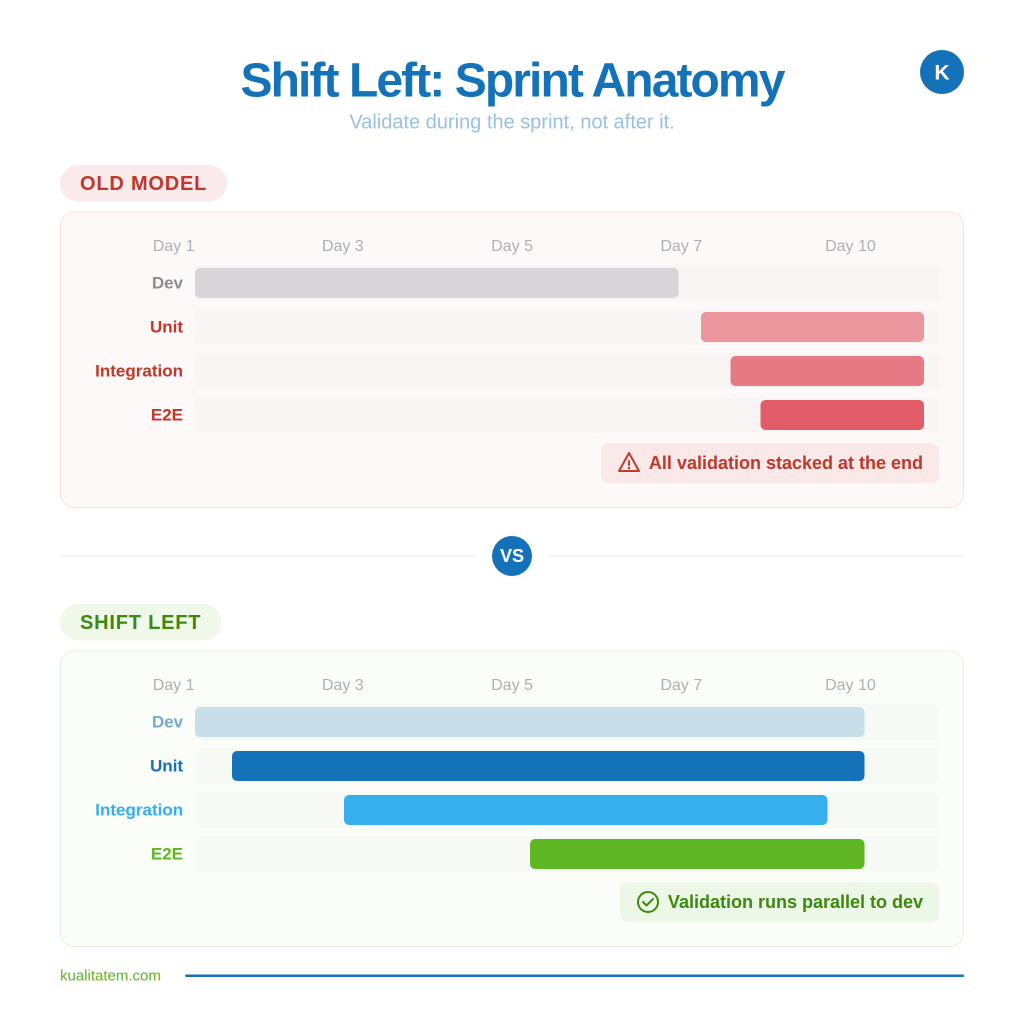
Shift-left testing moved validation earlier in the development lifecycle. Instead of finding defects right before release, teams caught them during development, when fixes were cheaper and simpler. For organizations running monolithic codebases with monthly release cycles, this was a genuine improvement.
Early bug detection reduced rework costs. Faster feedback loops shortened development cycles. Developers and testers started collaborating before code was “done,” not after. These are real gains. Nobody is arguing that they should be reversed.
The question is whether early-stage validation alone can protect a system that looks nothing like the one shift-left was designed for.
A single user interaction in a modern enterprise application might touch 30 microservices, several external APIs, a feature-flag layer, a CDN, and a data store that ships schema changes on its own schedule. The pipeline is no longer a straight line from development to production. It is a network of interdependent systems, and a quality strategy designed for a line break when it meets a network.
IBM’s research proved that catching defects early saves money. That math still holds. But it assumed a sequential pipeline where “early” was a single, identifiable stage. Capgemini’s World Quality Report 2024-25 found that 60% of organizations still cannot replicate production-like test environments. Most pre-production validation runs against mocks and approximations. The failures that actually reach customers happen in conditions that mocks never modeled.
Shift-left is not wrong. It just covers one layer of a system that has several.
AI-assisted coding tools such as LLMs, chatbots, and Multi-Agents increased how fast teams produce code. They did not increase how thoroughly that code gets validated. The numbers from 2025 tell the story clearly: 63% of organizations deploy faster thanks to AI coding assistants, but 59% report that AI-generated code needs significantly more debugging. 72% have traced production incidents directly back to AI-written code.
More output, shipped faster, through the same validation infrastructure that was already stretched. When the volume of code doubles but the scope of validation stays fixed at one stage, the risk does not stay flat. It compounds.
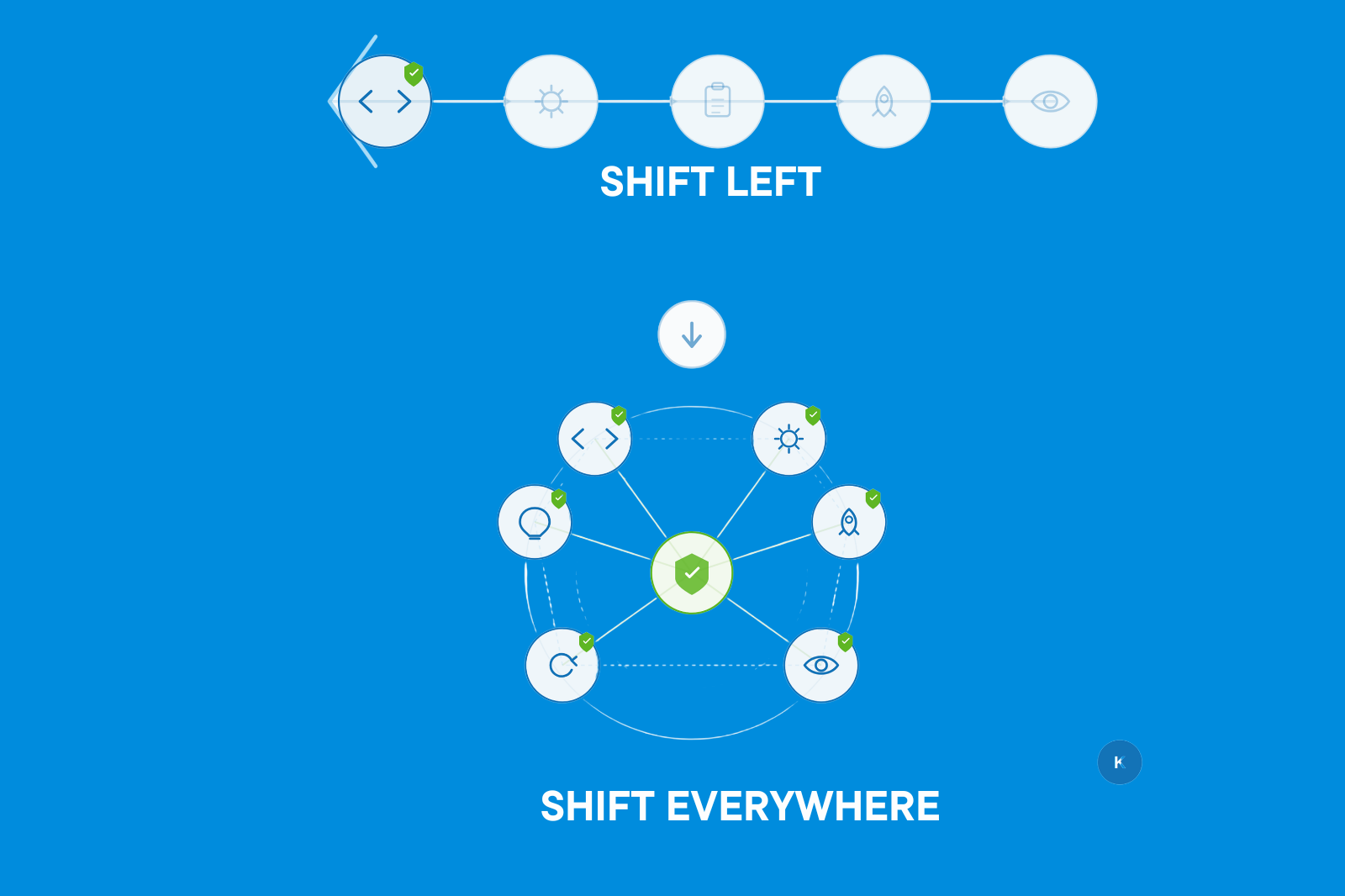
Shift-everywhere testing means that quality checks run all the time across the entire software lifecycle from development to deployment, through live production, and back into feedback. It doesn’t replace early testing; it builds on it and adds checks where serious problems usually happen.
This approach spreads responsibility for quality across engineering, operations, and security, instead of leaving it to a single team. Leadership focuses on meaningful metrics like incident frequency, detection speed, recovery time, and production bugs, rather than just test pass rates or coverage percentages.
Google’s DORA 2024 State of DevOps report showed that elite performers maintain a change failure rate below 5% while deploying on demand. They do not achieve this by stacking more pre-merge checks. They achieve it by integrating validation into every stage, including production.
| Aspect | Shift-Left | Shift-Everywhere |
| Focus | Early code validation | Continuous system-wide validation |
| Scope | Code-level | Full delivery lifecycle |
| Risk Coverage | Pre-production only | Development, staging, and runtime |
| Metrics | Coverage %, pass rate | Incidents, MTTR, production defect leakage |
| Outcome | Early feedback | System resilience under real conditions |
1- Early Detection is where shift-left lives: static analysis, dependency scanning, secure coding practices baked into IDEs and CI/CD. This layer catches known categories of defect before code leaves the developer’s machine. It is necessary. It is also the only layer most organizations have invested in.

2- Secure Deployment validates what happens between merge and production. Infrastructure-as-Code scanning, policy enforcement, and configuration validation catch the class of failure that comes from how code is deployed, not how it was written. Most enterprise pipelines skip this entirely.
3- Runtime Protection covers the risks that only exist once real users interact with the system. Web application firewalls, runtime application self-protection, and real-time monitoring detect threats like DDoS attacks, API abuse, and privilege escalation. No pre-release test can simulate these because they are inherently production phenomena.
4- Continuous Feedback closes the loop. Post-incident analysis feeds learnings back into development so that each failure improves future releases. Without this, the same category of bug gets fixed in isolation and reintroduced two sprints later. If an incident does not change behavior, the cost gets paid twice.
Coverage percentages and test pass rates only show that tests were executed they do not prove the system works in real conditions.
The Metrics That Truly Matter for CTOs:
If your current reporting does not include these five metrics, your quality dashboard is showing activity, not outcomes.
Shift-Everywhere Extends, It Does Not Replace
Shift-everywhere does not require scrapping your existing investment. It requires extending it.
Step 1: Map Your Current Validation
Start by mapping where your current validation actually runs. Most organizations find they cover one, maybe two layers.
Step 2: Add Deployment-Stage Validation
Add deployment-stage validation next, because that is where misconfigurations slip through most often.
Step 3: Introduce Runtime Monitoring
Introduce runtime monitoring for your highest-risk user journeys.
Step 4: Build Feedback Loops
Build feedback loops that connect production incidents back to development priorities.
Step 5: Align the Teams
Engineering, security, and operations need shared accountability for production outcomes, not separate scorecards.
Step 6: Redefine What You Measure
Redefine what you measure: move from activity metrics (tests executed, coverage achieved) to outcome metrics (failures prevented, incidents reduced).
Step 7: Iterate
Then iterate. The organizations that get this right did not do it in a single quarter. They piloted on one service, proved the value, and expanded.
Kualitatem has been building this model for over 16 years, operating at TMMi Level 5 with ISO 27001 compliance. Across Fortune 500 banking platforms, government systems, and high-growth SaaS products, clients implementing lifecycle-wide validation report 300% ROI on their quality investment, fewer repeated production failures, and release cycles that are both faster and safer. When validation is distributed instead of concentrated, the quality function stops being a bottleneck and becomes the reason releases hold up under real-world load.
Is shift-left testing outdated?
No. Early-stage validation still reduces cost and catches a meaningful category of defect. But it was designed for linear pipelines, and modern systems are not linear. Shift-left is the foundation. It is not the whole building.
What exactly is shift-everywhere testing?
A validation strategy that runs across development, deployment, runtime, and feedback. Instead of concentrating all checks in one stage, it distributes them to match where failures actually originate.
We have automation and our pipeline is green. Why are bugs still reaching production?
Pre-production tests validate code against controlled conditions. Production failures come from real user behavior, infrastructure variability, third-party changes, and traffic patterns that no mock can fully replicate. The gap between controlled and real is where production bugs live.
Shift-left is not dead. But treating it as a complete quality strategy is how organizations end up with green pipelines and recurring production incidents. The teams with the strongest production stability validate at every stage, measure outcomes instead of activity, and treat quality as something that runs continuously rather than something that happens once before release.
If that does not describe your current setup, the gap between what your metrics show and what your customers experience is probably wider than you think.
We build shift-everywhere programs for enterprises where production failures carry real cost. Let us show you what the transition looks like.







Our experts are all ready. Explain your business needs, and we’ll provide you with the best solutions. With them, you’ll have a success story of your own.
Contact us now and let us know how we can assist.