
Data Quality, Cleansing, Integration & Migration
DATA MIGRATION METHODOLOGY
One of the most important commodities that a business controls, owns, or maintains is its ‘data’ and therefore, any data migration is a high-risk activity. As a result, it must undergo significant verification and validation efforts.
1.1 EXERCISING DATA MIGRATION TASK
The core of exercising a data migration task is to perform an (ETL) ‘Extract, Transform, and Load’ operation that extracts the data from various sources, fixes/transforms it, and then loads it into the target data warehouses. This offers our testing team some of the key consideration points to help them effectively plan tests and strategize accordingly for data migration activities
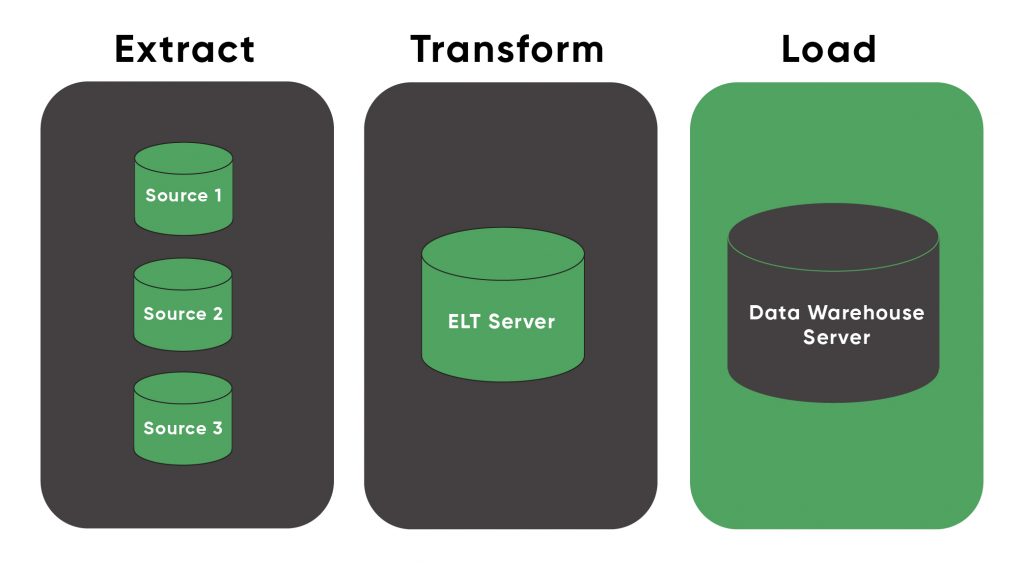
1.2 DATA MIGRATION PHASES
Following are the phases of data migration activity.
1.2.1 PRE-MIGRATION TESTING
We include a series of activities before pre-migration testing to execute before the actual data migration activity. This helps us in understanding the mapping of the data from its original source to the destination location and in highlighting the inconsistencies. The severity of these inconsistencies helps us decide if the system needs a design change or a business process change to enable data migration to target location successfully.
- Review the design document or detailed requirements
- Understand and define the source and scope of data (Extraction Process)
- Define the extraction process, number of records, number of tables, relationships, etc.
- Understand all the suppliers of the data into the system.
- Review ERD (Entity Relationship Diagram), data dictionary, or similar documents available for the current legacy system.
- Understand and define the target data-warehouse (Load Process)
- Review ERD (Entity Relationship Diagram), data dictionary, or similar documents available for the current legacy system.
- Understand the data scheme including mandatory fields, field names, field types, data types, etc. for both the original data source and the destination system
- Understand the data cleaning requirements
- Understand any interfacing with other systems
Once done with the above steps, we:
- Correct mapping to the user interface
- Correct mapping to the business process
- Configure the software testing tool
- Correct scripts generation using the field details mentioned above.
- Identify sample subset data (review with the client to get approval and minimize the risks)
Understand business cases, user stories, and use cases
1.2.1.1 Data Cleansing
Data cleansing is of vital importance during the data migration activity and it is very likely that incorrect data may be present within the migrated data set. We do data cleansing through the data validation during input through ‘Field Validation’ and ‘Error Checking’ as this is by far a cheaper and efficient method.
Data cleansing tasks are overlapping tasks. We perform them across the pre-migration, migration and post-migration phases.
The core purpose of data cleansing activity is to 1) identify incomplete, incorrect, inaccurate, and irrelevant data, 2) replace it with correct data, 3) delete dirty data and 4) bring consistency to different data sets that merge from different sources.
Preparation for Data Cleansing Activity:
- Understand error types
- These may include blank fields, too-long data lengths, or bad characters, among many others.
- Interrogate data in order to find the potential error types established above.
- Identify data checking method
- Interrogate through the database using SQL commands.
- Use data cleansing tools.
- Understand data linkages
- Data change in one table may corrupt the data in another linked table if the same updates are absent across the entire system.
Data Cleansing Steps:
We perform the following steps for data cleansing
- Data Parsing: With data parsing, we locate and identify individual data elements in the source files and then isolate these data elements in the target files.
- Data Correction: We correct/fix data using tools or secondary data sources.
- Data Standardization: We bring data to the standard format as per the standard and customized business rules.
- Data Matching: We do data matching on the data processed through the above steps to eliminate any duplications as per the defined business rules.
- Data Consolidation: We analyze data processed through all the above steps to identify any relationships between the matched records. We then consolidate/merge this data into one representation.
1.2.2 POST-MIGRATION TESTING
After completing the migration activity, we perform black box testing/acceptance testing against business cases, use cases, and user stories. We use the same data subsets for post-migration testing that we used during the pre-migration testing. We perform this activity in a test environment, not the production one.
1.2.2.1 Post-Migration Activities:
- Test the throughput (number of records per unit time) of the migration process. We conduct this testing to be sure that the planned downtime is sufficient.
- Verify the completeness and integrity of the migrated data.
- Verify the record counts of the migrated data just to be sure that all the data is migrated. Record count match only displays if data migration is complete or not. It doesn’t show the internal details like duplication, correctness, integrity, and other data characteristics.
- Verify that the content migration is as per the specifications. We perform this testing using sampling of data or some automation tools.
In addition to testing the known business flows, our testers carry out the following tests. We also carry out negative testing approaches, which primarily ensure that data cleansing takes place at run time within the system:
- Input bad data: We try to violate the validation rules including the use of boundary value analysis, equivalence partitioning, and error guessing. The validation at the user interface level should be in accordance with the validation at the database level. We treat as a defect if no validation is imposed or if the validation between the database and the user interface do not match.
- Bypass mandatory data: We try to navigate to further steps of a use case within the system prior to the fulfillment of all data requirements.
- Checking data locks: It should not be possible for multiple users to access the same new record within the database. Normally, the database manages this level of validation so the risk may be minimal. But this testing should be carried out where required.
- Conversions testing: We ensure that the data, when requesting from the database(s) displays according to the user.
- Non-functional testing: We perform security testing, performance testing, and usability testing, etc.
1.2.3 USER ACCEPTANCE TESTING
We perform user acceptance testing after the post-migration testing phase as the functional fragilities as a result of the consolidation of the migrated data may be difficult to point out in the previous phases. We do this to interact with the legacy data in the destination system before we release it to the production environment.
1.2.4 PRODUCTION MIGRATION
We understand that the execution of the above phases successfully does not guarantee that the production process will be errorless. Some of the challenges/areas that we take care of at this stage are.
- Procedural slips.
- Production system configuration errors.
- In case we use automated software testing tools during the above phases, we prefer to execute those scripts here again. Otherwise, we perform sampling or summary verification.
1.3 DATA QUALITY TOOLS
Following are some of the areas that DQ tools can help with,
- Cost and Scope Analysis
- Migration Simulation
- Data Quality Rules Management
- Migration Execution Sequencing
- Independent Data Migration Validation on Target System
- Ongoing Data Quality Assurance
Following are some of the tools for data integration and migration activity:
Tools:
- Adeptia
- Actian
- Attunity
- Denodo
- Microsoft SSIS
- Oracle Data Integrator
- SAP – Data Services
- talend-Open Studio for Data Integration
- TIBCO – Data Virtualization
- Hitachi Vantara – Pantaho Data Integrations
- Informatica – PowerCenter
- IBM – InfoSphere DataStage
- SAS
- Syncsort – DMX-h
- CloverETL
- Jedox
- DQGlobal – appRules
- Winpure – Clean & Match
- DTM Data Scrubber
- Data Ladder – DataMatch Enterprise
Let’s Build Your Success Story
Our experts are all ready. Explain your business needs, and we’ll provide you with the best solutions. With them, you’ll have a success story of your own.
Contact us now and let us know how we can assist.